之前只是听说过python可以使用beautifulsoup或者是selenium之类的库进行爬虫的操作,也听说过一些理论,例如能爬API就爬API,爬不了API再去爬网页。
这次需要自己手动的去爬取存储漏洞代码的网站SARD以及Github commit。
爬取漏洞代码
其实这里我是用selenium模拟了浏览器的这样一个功能,但是后面发现只要爬API就行了。
Selenium模拟浏览器
首先需要安装相应浏览器的驱动,我用Edge比较多,因此选择了Edge的driver,实际上你用哪个就在网上下哪一个然后安装到和python安装目录一样的路径下就ok了。
观察这个网页,发现我们需要找的代码其实是一个滚动的状态,就是说随着鼠标的下滑,它之前的代码会从页面消失,后续的代码会在页面展现,单纯的使用一个selector根据它的class来提取里面的代码肯定是不行的。
我采取的解决方法是模拟鼠标滑轮的方法,先观察一下它到底是怎么滑的,来确定每次下滑的合理的px区间,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| def scroll_and_extract_code(driver):
code_content = ""
js_code = "return document.querySelector('#right-pane > code > div > div.CodeMirror-vscrollbar').scrollHeight;"
total_height = driver.execute_script(js_code)
while True:
js_code = """
var codeContent = "";
var elements = document.querySelectorAll('.CodeMirror-line:not(.processed)');
elements.forEach(function(element) {
codeContent += element.textContent + "\\n";
element.classList.add('processed');
});
return codeContent;
"""
new_code_text = driver.execute_script(js_code)
code_content += new_code_text
js_code = """
var el = document.querySelector("#right-pane > code > div > div.CodeMirror-vscrollbar");
el.scrollTo(0, el.scrollTop + 760);
"""
driver.execute_script(js_code)
time.sleep(1)
js_code = """
var el = document.querySelector("#right-pane > code > div > div.CodeMirror-vscrollbar");
return {
scrollTop: el.scrollTop,
clientHeight: el.clientHeight
};
"""
element_scroll_info = driver.execute_script(js_code)
if element_scroll_info["scrollTop"] + element_scroll_info["clientHeight"] >= total_height:
try:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.CodeMirror-line:not(.processed)')))
except:
break
return code_content
|
这样就可以一次性的爬取一个网页里面我们需要的内容,同时,这里的小trick就是使用一个js代码对于查找过的相应的内容进行记录:
1
2
3
4
5
| var elements = document.querySelectorAll('.CodeMirror-line:not(.processed)');
elements.forEach(function(element) {
codeContent += element.textContent + "\\n";
element.classList.add('processed');
});
|
通过这样的手段就可以完整的提取内容同时不存在内容重复或者遗漏的问题啦,但是用selenium模拟的最大缺点就是:太慢了,所以我们还是要争取使用爬取API这种方法来进行内容的获取。
其实感觉selenium就是写点js脚本然后用python运行?
爬取API
首先打开这个网页,F12之后点击网络的选项,然后刷新网页,看看它传过来的什么东西。
理论上来说,页面上展示了我们需要的代码,那么肯定是从后台获取过来的。这样我们就有两种爬取的策略:
- 第一种,如果不是通过后台的API获取的话,我们可以观察一下这个动态的代码是如何生成的。它肯定是通过某种
js代码来实现的,因此我们可以分析那个js代码,让它完整的展现代码即可。
- 第二种,也是比较简单易懂同时也是我们采取的这种方法:寻找一下它爬取的API。如果能找到它的API,那么直接
requests.get()即可。
我们检查一下这个网页:
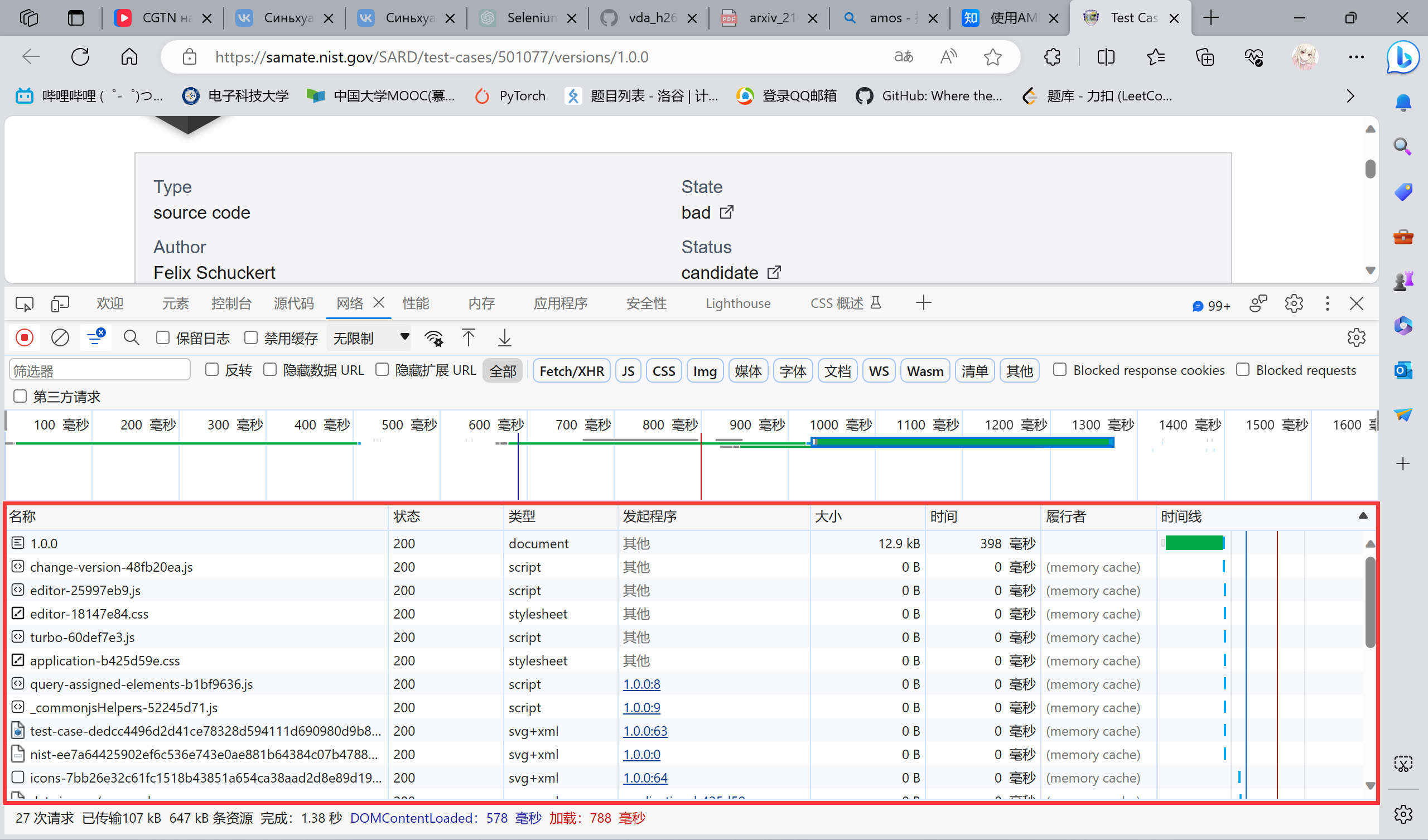
首先反正可能不可能是那些什么icon啊,css啊之类的,由于这个网站比较友好,我们可以很清楚的看见:
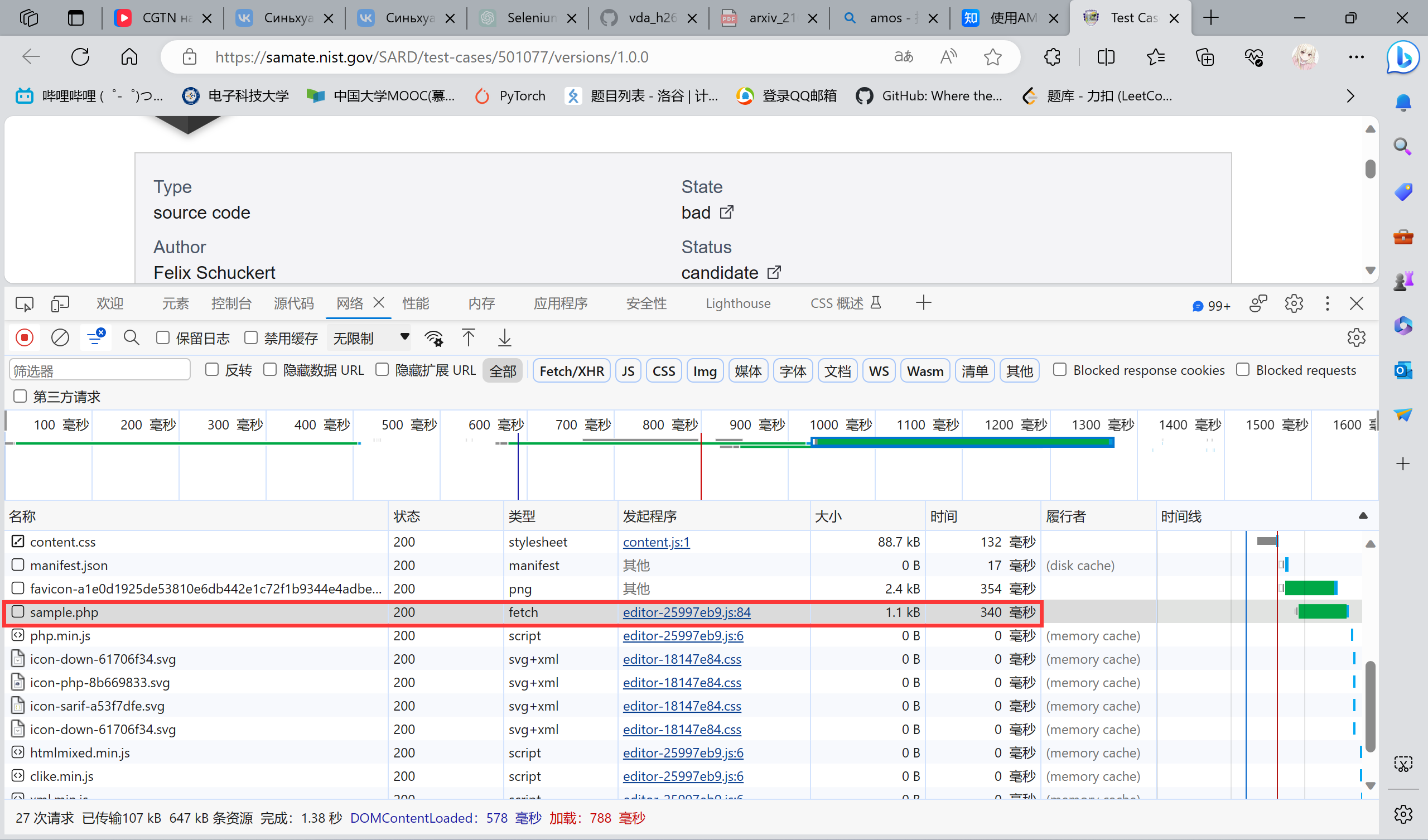
ok,他都叫sample了不如点进去看一下,然后我们就跳转到这个网页:
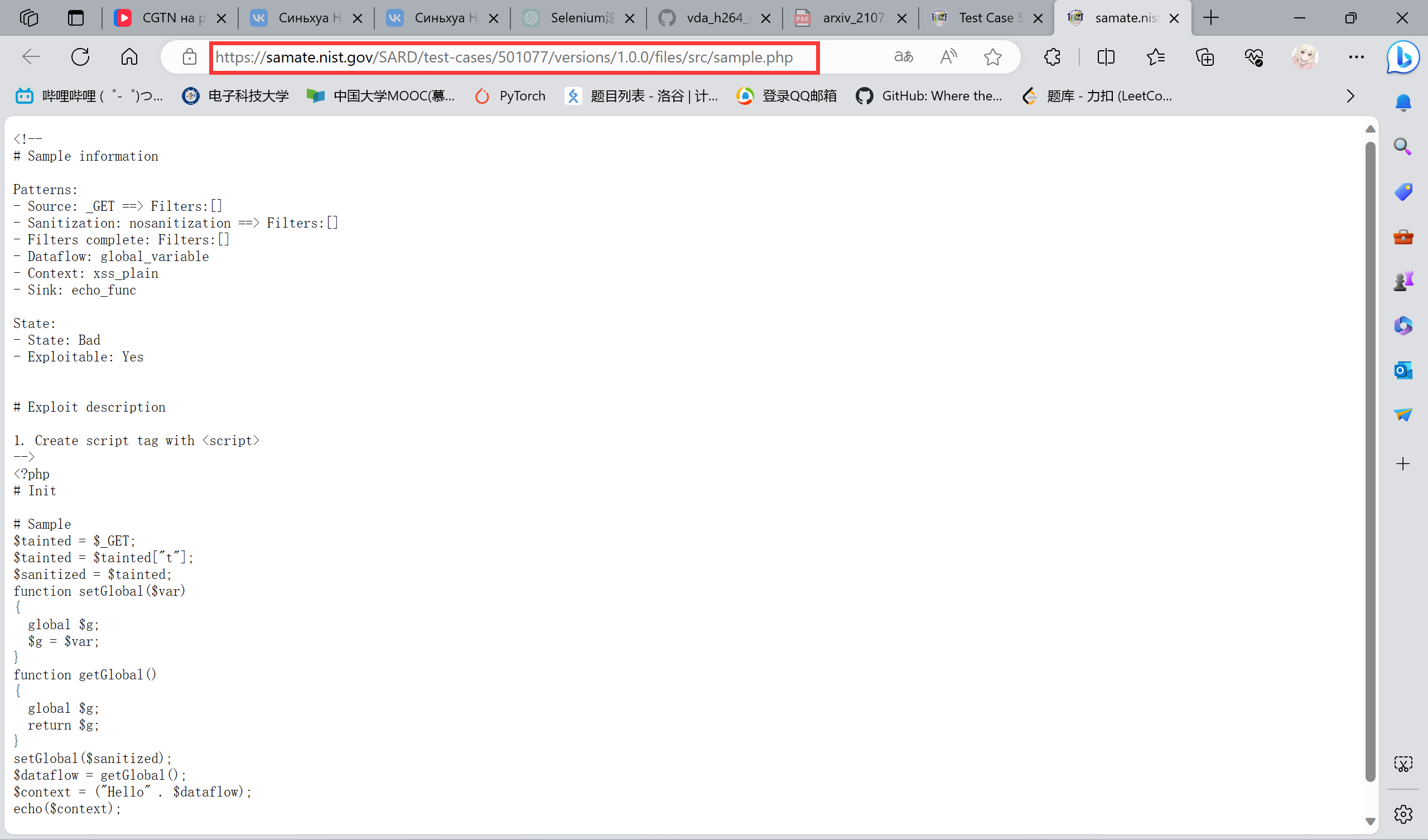
合理推测,后面的代码都会是这种形式,然后就发现推测对了。同时这个网站提供了这个东西的uri,可以通过它的API来获取,那就没有什么疑难的问题要解决了,后续就交给requests.get()和时间慢慢爬就行了。
爬取GitHub的commit